On reddit, a PostgreSQL user was trying to use the SQL database as a document database, with all data in a JSONB column, but faced a performance issue with a simple GROUP BY on 100 millions rows:
Select (data->>referenceId), count(*)
From items
Group by (data->>'referenceId')
having count(*) > 1;
Some suggested creating an expression index, which the user had already implemented, while others proposed moving this field to a table column, a solid suggestion. Additionally, many requested the execution plan. Overall, this thread features valuable insights from knowledgeable contributors. Depesz added a wise recommendation:
For starters, putting everything in json is going to cause serious performance and storage problems sooner or later.
You can create GIN indexes on JSON fields in PostgreSQL, but those will not help with ORDER BY or GROUP BY because they use Bitmap Scan which doesn't provide range or sort like regular B-Tree indexes.
It is possible to use B-Tree index on JSON fields in PostgreSQL, but only if there's no array in the path. Fortunately, it is the case here.
To investigate, I create the table with a field in JSON but also as a column, to compare both possibilities:
create table items (
id bigserial primary key,
referenceId text,
data jsonb not null
);
insert into items (referenceId,data)
select '42', jsonb_build_object( 'referenceId', '42', 'filler', repeat('x', 4000) )
from generate_series(1,1000000)
;
On the regular column, I can create a regular index. On the JSON field, I can create an expression index:
create index on items( referenceId );
create index on items( ((data->>'referenceId')) );
To avoid a full table scan without inserting too many rows, I disable it (there's no query planner hints in PostgreSQL, unfortunately) and I vacuum the table to ensure a fresh visibility map:
set enable_seqscan to off;
vacuum analyze items;
A GROUP BY on the regular column uses the index efficiently, with an Index Only Scan (because all necessary columns are covered by the index entry) and no Heap Fetches (because it was freshly vacuumed):
explain (analyze, verbose, buffers, costs off, serialize text)
Select referenceId, count(*)
From items
Group by referenceId
having count(*) > 1;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------
GroupAggregate (actual time=181.750..181.750 rows=1 loops=1)
Output: referenceid, count(*)
Group Key: items.referenceid
Filter: (count(*) > 1)
Buffers: shared hit=1 read=844
-> Index Only Scan using items_referenceid_idx on public.items (actual time=0.045..84.469 rows=1000000 loops=1)
Output: referenceid
Heap Fetches: 0
Buffers: shared hit=1 read=844
Planning:
Buffers: shared hit=8
Planning Time: 0.113 ms
Serialization: time=0.006 ms output=1kB format=text
Execution Time: 181.777 ms
(14 rows)
This is the best plan, reading 844 pages to aggregate one million rows. Can we have the equivalent with an expression-based index on a JSON field? Unfortunately not:
explain (analyze, verbose, buffers, costs off, serialize text)
Select (data->>'referenceId'), count(*)
From items
Group by (data->>'referenceId')
having count(*) > 1;
QUERY PLAN
---------------------------------------------------------------------------------------------------------
GroupAggregate (actual time=1081.667..1081.668 rows=1 loops=1)
Output: ((data ->> 'referenceId'::text)), count(*)
Group Key: (items.data ->> 'referenceId'::text)
Filter: (count(*) > 1)
Buffers: shared hit=9108 read=8978 written=1819
-> Index Scan using items_expr_idx on public.items (actual time=0.030..983.316 rows=1000000 loops=1)
Output: (data ->> 'referenceId'::text)
Buffers: shared hit=9108 read=8978 written=1819
Planning:
Buffers: shared hit=6
Planning Time: 0.101 ms
Serialization: time=0.004 ms output=1kB format=text
Execution Time: 1081.693 ms
(13 rows)
There's no Index Only Scan, the Index Scan had to read the table, with 10x more pages read. In my case, the JSON is not too large and well compressed, but this could be worse.
The issue arises not from the JSONB datatype itself, but because it must be indexed with an expression. The PostgreSQL query planner does not expand this expression to recognize that the index is covering the query. This is documented as:
PostgreSQL's planner is currently not very smart about such cases. It considers a query to be potentially executable by index-only scan only when all columns needed by the query are available from the index
The workaround is to add the underlying columns in the INCLUDE clause, but you cannot have expressions there, and adding the whole JSON field would defeat the goal.
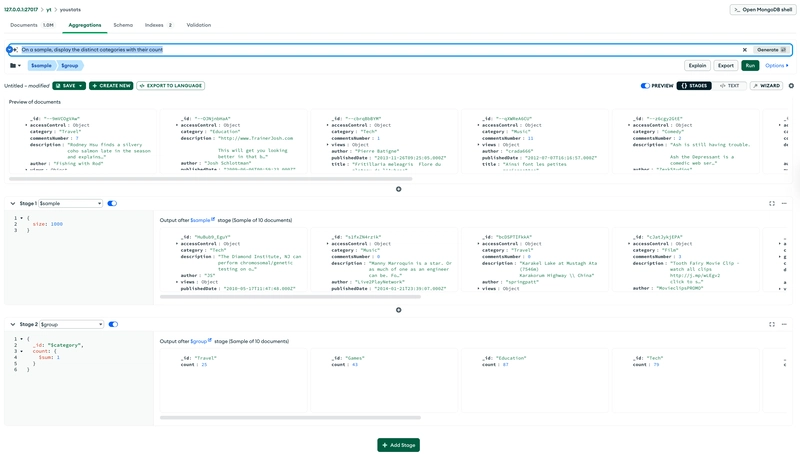
The solution is to use a SQL database for what it's made for, with columns in tables, especially for what must be indexed, the schema-on-write part. If you want to use a document database, then MongoDB has no problem on indexing fields in JSON:
db.items.createIndex( { referenceId: 1 } )
db.items.aggregate([
{ $match: { referenceId: { $gt: MinKey } } }, // to skip inexisting field
{ $group: { _id: "$referenceId", count: { $sum: 1 } } },
{ $match: { count: { $gt: 1 } } },
{ $project: { referenceId: "$_id", count: 1 } }
]).explain();
...
queryPlan: {
stage: 'GROUP',
planNodeId: 3,
inputStage: {
stage: 'PROJECTION_COVERED',
planNodeId: 2,
transformBy: { referenceId: true, _id: false },
inputStage: {
stage: 'IXSCAN',
planNodeId: 1,
keyPattern: { referenceId: 1 },
indexName: 'referenceId_1',
isMultiKey: false,
multiKeyPaths: { referenceId: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { referenceId: [ '(MinKey, MaxKey]' ] }
}
}
}
...
MongoDB doesn't need expression indexes on document fields, and can efficiently get the entries sorted to cover the projection and grouping without additional hashing or sorting. explain() shows how the index is used.
In PostgreSQL, you need to normalize the indexed keys to columns instead of JSONB fields to achieve comparable indexing performance. It's important to note that MongoDB emulations on PostgreSQL use GIN or RUM indexes, which are not suitable for range, sort, or group optimizations, leaving the issue unresolved. Only MongoDB can provide native performance on documents.
To utilize databases effectively, employ relational databases for their intended functions, a normalized use-case agnostic schema, and document databases for theirs, optimized for the domain access patterns. This approach maximizes the unique strengths of each database type, ensuring optimal usage.
by Franck Pachot
{kind=link}
{kind=link}
{kind=link}
{kind=link}